

NLP Transformer 이후 연구 동향
Transformer
Transformer
- 이전의 문제점:
- Long-Term Dependency
- Gradient Vanishing and Exploding
- 해결방안: 👍
- RNN 구조를 사용하지 않고 Attention만을 사용하여 학습
- RNN 구조가 아닌 아키텍쳐에서 Attention을 사용하기 위해 Self Attention을 고안
- 결과:
- Language Model의 Game Changer...
- 이후 나오는 모델들은 대부분(전부) Transformer의 구조를 응용한다.
GPT 1
GPT-1 | ( 참고1 , 참고2 )
- 이전의 문제점:
- Unlabeled 텍스트 데이터는 풍부한 반면, Labeled 데이터는 매우 적은 문제
- → supervised learning을 적용하기 어려움
- Unlabeled 데이터를 이용하기 위한 Unsupervised learning의 경우는 optimization objective를 결정하기 어려움
- 또한 supervised learning의 경우 다른 task로 transfer learning을 시키기 어려움
- 해결방안:
- Supervised learning과 Unsupervised learning을 섞은 Semi-supervised learning을 적용→ (fine-tuning) Supervised learning은 Input representation을 조정해 위의 pretrained model에 넣어줌
- → (pretrained model) Unsupervised learning은 transformer 구조의 decoder 파트만 12개 가져와 모델 생성
- 결과: 더 좋은 성능, 다른 NLP task에 쉽게 transfer learning 가능
BERT
BERT
- 이전의 문제점:
- 이전 모델들(GPT1, Auto regressive 기반 모델들) 데이터의 방향성이 있어서 양 방향에서 문맥을 고려해야 하는 경우는 효과적이지 못했다.
- 해결방안:
- 각 데이터 일부를 [mask]로 바꾸어 양방향 context를 기반으로 그것을 맞추게함 (Masked Language Model, MLM)
- 결과: 수많은 NLP 태스크에서 SOTA를 달성
GPT2, 3
GPT-2 | GPT-3
- 이전의 문제점: 이전의 문제는 모르겠고, GPT 1 성능 늘릴거야~ SOTA 갈끄니까~
- 특징:
- GPT-2: zero-shot의 경우에도 괜찮은 성능을 냈으며 특정 단어를 문장의 마지막에 줌으로써 여러 task를 수행
- GPT-3: zero-shot, one-shot, few-shot 등을 실험했으며 예시 데이터가 많을수록 성능 향상. 더 많은 데이터, 더 많은 배치 사이즈
- 결과: 성능 업
- 문제점 : 컴퓨팅 파워가 매우 많이 소요됨
- 파라미터 수 : GPT1 < GPT2 = GPT1 * 10배 < GPT3 = GPT1 * 1000배
XLnet
XLnet
- 이전의 문제점:
- GPT 같은 Auto Regressive 모델은 양 방향 문맥을 고려해야 하는 경우는 비효율적임
- BERT 같은 MLM 모델은 mask들의 dependency를 반영 못한다.
- 사전 학습 때만 mask가 등장하고 finetune 시점에는 존재 하지 않는다.
- 목표:
- 저 둘의 장점만을 취하겠다.
- 즉 dependency도 가져가면서 양 방향 문맥도 고려하겠다.
- 해결방안:
- Permutation Language Modeling 사용
- Two-Stream Self-Attention 도입
- Transformer-XL 구조
- 결과:
- (나온 당시 : 2019년 6월) 20개 Task에서 SOTA
ALBERT
ALBERT
- 이전의 문제점:
- 메모리가 너무 많이 소요됨.
- 학습 시간이 너무 오래 걸림
- 너무 깊어질 경우(L, H) 모델 성능 감소
- 해결방안:
- Factorization Embedding Parameterization
- Cross-layer Parameter Sharing
- Parameter를 sharing 하여 모델이 깊어지지 않게 함. 파라미터가 줄어들며 성능이 하락하긴 하지만 하락폭이 미미함.
- Sentence Order Prediction
- 문장의 순서를 예측하는 새로운 방식을 적용. 인접한 문장의 순서를 바꾸어 논리적 흐름을 학습하도록 함. self-suprevised loss 제안을 함으로써 성능 향상
- 결과: 모델 크기 줄이고 학습시간도 빠르게 하며 성능향상, 그러나 ALBERT도 클수록 성능 잘나옴.
ELECTRA
ELECTRA
- 이전의 문제점:
- MLM에서 15%의 [MASK] 토큰만 학습하는 방식의 비효율성
- pre-train에만 사용되고 fine tuning에는 사용되지 않는 [MASK] 토큰
- 해결방안:
- [MASK] 토큰 자리에 대체 단어를 생성하고 전체 단어가 original 인지 corrupted token 인지 예측하는 replaced token detection 을 통해 학습이 진행
- 대체 단어를 generator 로 생성하고 이를 discriminator 로 진짜인지 가짜인지 판별하는 방식으로 학습
- 결과:
- 모든 input token 을 판별하기 때문에 masking 된 token 만 예측하는 MLM 보다 더 효율적이고 같은 model size, data, compute 를 가진 BERT 보다 더 좋은 성능을 냄
- RoBERTa, XLNet 의 1/4 만큼의 계산량으로 성능 비슷하고 같은 계산하면 더 좋음
Light-weight Models
- 참고 | TinyBERT | DistillBERT
- 이전의 문제점:
- 모바일기기 같은 비교적 리소소가 제한된 기기에서 쾌적하게 돌릴 수 있는 모델의 필요성을 느낌
- 해결방안:
- DistillBERT, TinyBERT 논문에서 large 모델에서 compact 모델을 만들어내는 방법을 제안
- 기존 large 모델보다 경량화된 모델을 제안했음
- TinyBERT 실험
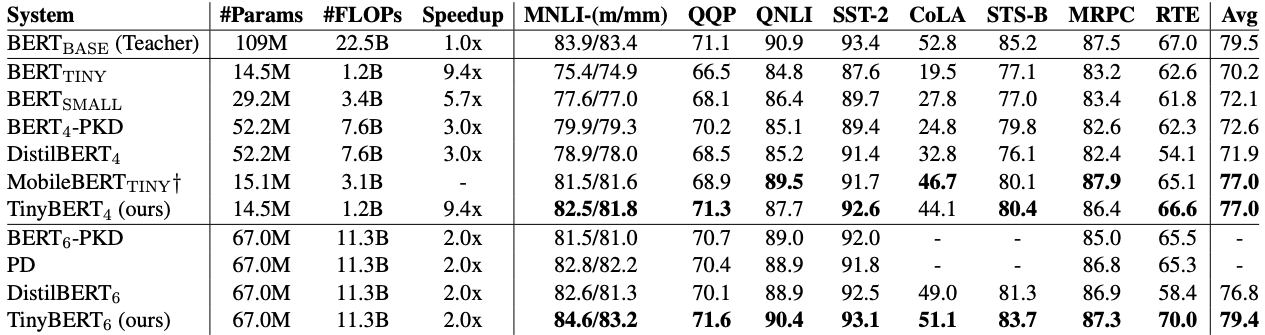
- 4 레이어 TinyBERT의 경우 다른 경량화 모델보다 빠르면서 성능을 유지
- 6 레이어 TinyBERT의 경우 BERT_BASE 보다 작은 파라미터와 FLOPs를 가지면서 성능은 비슷하게 유지됨
- 결과: 어느정도 경량화된 모델로도 정확도를 유지하는게 가능해짐
Fusing Knowledge Graph into Language Model
- ERNIE | KagNET
- 이전의 문제점:
- 기존의 BERT와 같은 pre-trained model은 주어진 문장에 포함되어 있지 않은 추가적인 정보가 필요한 경우에는 해당 정보를 효과적으로 활용하지 못함.
- 해결방안:
- 주어진 문장에서 담고 있는 정보 뿐만 아니라, 개체를 정의하고 그들간의 관계를 정형화해 만들어 둔 지식 그래프(Knowledge graph)를 잘 결합하여 문제를 해결
- e.g. ERNIE, KagNET
BART
![[부스트캠프][WK07 / Day34] 7주차 NLP Transformer 이후 연구 동향 정리](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FyY9aN%2Fbtrfp2WCpfH%2FKpPXNX7zKVpUlLGlJYLiuk%2Fimg.png)